Before You Read: Quick AI Engineering Opex Reduction Check
Before diving into the guide below, use this quick check to identify where engineering operating costs may already be increasing across your delivery lifecycle.
Check Your Current State
Look at your last few release cycles.
Are teams spending more time validating releases than building features
Do production issues regularly disrupt planned sprint work
Are senior engineers repeatedly pulled into debugging or explaining legacy modules
Are maintenance and bug fixing consuming a growing share of development capacity
Do releases slow down as integrations and product complexity increase
Are QA cycles expanding even when team size remains the same
Do small changes require large regression effort before deployment
If the answer is yes to even one, engineering Opex is increasing quietly inside everyday delivery work.
Cost rarely rises because of a single decision. It grows through repeated effort required to safely make change.
Start With What You Already Have
Engineering Opex reduction does not begin with large transformation programs.
Start by identifying:
A workflow where similar defects are repeatedly fixed
A release path that consistently delays deployment
A module responsible for recurring incidents or maintenance effort
A validation activity consuming disproportionate engineering time
A knowledge dependency concentrated with a few senior engineers
Select one area and run a focused 30 day AI assisted pilot.
Most measurable savings come from removing repeated effort, not accelerating development everywhere at once.
Software engineering rarely becomes expensive because teams build too much software.
It becomes expensive because changing software takes more effort over time.
Across mature product organizations, developers spend less than half of their time delivering new functionality. Industry research from Stripe’s Developer Coefficient and multiple DevEx studies shows that a significant share of engineering effort is consumed by debugging, validation, system understanding, and coordination required to safely release change. As products scale, delivery effort gradually shifts from innovation toward maintenance and risk reduction.
This shift has measurable financial impact.
The U.S. National Institute of Standards and Technology estimates that defects discovered after release can cost up to 15 to 100 times more to resolve than issues caught during development. Each escaped defect triggers investigation, retesting, coordination, and release disruption, turning small technical problems into recurring operating expense.
Large engineering organizations are already seeing how this compounds.
Microsoft’s internal studies on AI assisted development observed that developers using Copilot completed common implementation tasks significantly faster while reducing time spent searching documentation and understanding unfamiliar code. More importantly, teams reported fewer interruptions tied to routine coding, onboarding support, and repeated implementation work. The savings did not come from writing more code. They came from reducing the effort required to understand, validate, and maintain existing systems.
A similar pattern is emerging across SaaS and platform companies adopting AI assisted testing and repository analysis. Organizations focusing AI on regression heavy workflows have reported substantial reductions in validation cycles and escaped defects, allowing release cadence to move from multi week cycles toward continuous or weekly deployment without expanding QA or engineering headcount.
This marks an important shift in engineering economics.
AI does not primarily reduce cost by accelerating feature development. It reduces cost by lowering the recurring effort required to safely make change.
When applied to regression, rework, maintenance backlog, and code understanding, AI begins to remove the hidden operational drag that drives engineering Opex upward year after year.
This guide examines where engineering Opex actually accumulates, the AI capabilities that reduce it fastest, and how ISVs and product teams can realistically achieve measurable operating cost reduction without large scale rewrites or disruptive modernization programs.
Where engineering Opex actually bleeds money
Engineering Opex rarely looks like waste when you are inside the work. It looks like responsibility.
A team reruns regression because a release cannot afford surprises. A senior engineer helps a new hire understand a fragile module. QA raises clarification because a requirement was interpreted differently. Support escalates a defect and the sprint plan quietly bends around it.
Each action is reasonable. The problem is the cumulative tax.
Legacy code rework
Legacy code is not expensive because it is old. It is expensive because it is unclear.
The cost is often not the fix itself. The cost is understanding what the code is doing, what business rules still apply, where similar logic was duplicated, and what else might break if a change is made. This uncertainty slows reviews, delays refactors, and creates cautious delivery.
If this sounds familiar, this is exactly the pattern many teams face when dealing with app maintenance in legacy systems.
Escaped defects and bug leakage
Escaped defects, sometimes called bug leakage, are expensive because they trigger support, engineering, retesting, and coordination overhead all at once.
A production defect is never just a defect. It interrupts planned work, creates context switching across teams, and increases release risk for the next cycle. This is why bug leakage inflates Opex far beyond the cost of the individual fix.
Long QA cycles
Many teams believe they have a development speed problem when they actually have a test throughput problem.
Manual testing load, brittle automation, uneven coverage, and dependence on a few product experts can stretch QA cycles and slow the whole organization. Teams batch changes to reduce test overhead. Bigger releases increase risk. Increased risk leads to even longer QA cycles.
Regression overhead
Regression is the cost of maintaining confidence in a growing product.
As features, integrations, and configurations grow, every change carries more validation work. Small changes trigger large retest cycles. Release branches live longer. Merge friction grows. Teams release less often because testing becomes expensive.
This is one of the fastest growing components of engineering Opex in mature products.
Onboarding drag
A new engineer does not only cost their salary. They also consume senior engineer time.
When knowledge lives in tribal memory instead of documentation and patterns, onboarding becomes a repeating interruption system. The same explanations are repeated. The same fragile areas are avoided. The same senior people become bottlenecks.
Documentation debt becomes delivery debt
Poor documentation is not just a process issue. It directly increases cost.
Unclear specs create rework. Missing runbooks slow incident resolution. Undocumented architecture decisions make refactors harder. Unwritten edge cases push discovery into QA and production.
The common thread across all six leak points is simple. Teams spend too much effort answering the same questions over and over.
What does this module do
What breaks if I change it
Do we already test this scenario
Is this expected behavior or accidental behavior
That is why AI can reduce engineering Opex. It reduces the cost of understanding, validating, and repeating work.
The three AI capabilities that reduce Opex the fastest
AI does not reduce Opex just because it writes code. It reduces Opex when it lowers the cost of the most expensive recurring work in your engineering system.
The fastest gains usually come from three capability groups.
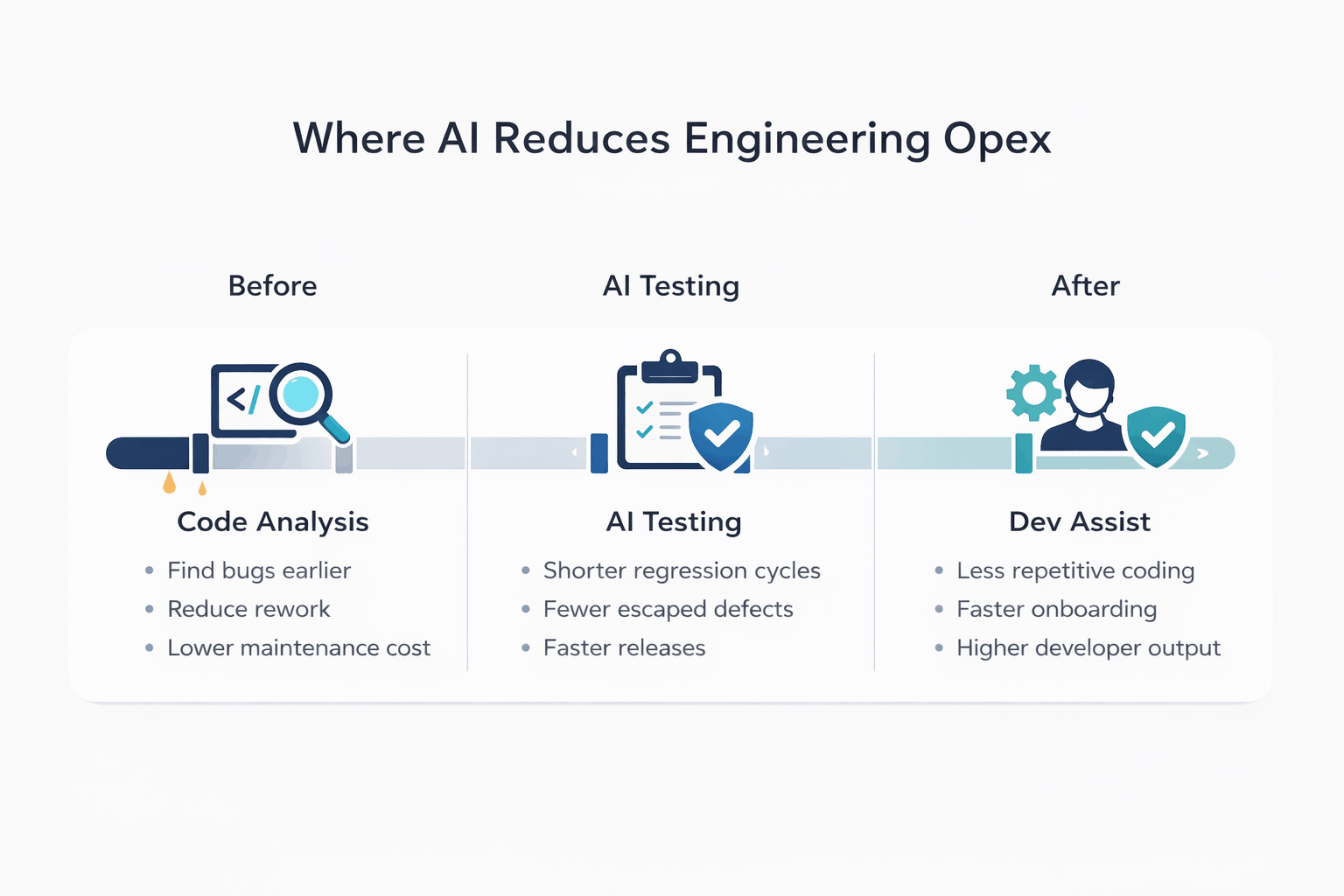
1) AI driven code analysis for bug and debt detection
This is the quickest way to make hidden cost visible.
In many products, debt is spread across duplicated logic, weak validation paths, dead code, missing tests, and fragile modules with high change churn. AI can scan repositories and surface patterns across the codebase faster than manual review alone.
The value is not in generating a giant debt list. The value is in prioritization. Teams can identify the modules that drive the most incidents and maintenance effort, then target fixes that reduce future rework.
This is where Opex reduction starts to become measurable because teams spend less time debugging repeat problems and less time reacting to known weak spots.
Typical impact range in targeted rollouts: 8 to 12 percent Opex reduction, especially when teams use AI analysis to reduce repeat bugs, debugging time, and future rework in high cost modules.
2) AI assisted development for repeatable implementation work
This is usually where people talk about speed, but the real value is cost control.
Developers lose a lot of time to repetitive implementation work such as scaffolding, wrappers, predictable transformations, mocks, and documentation drafts. AI can compress that time and reduce the amount of effort spent on low value code production.
A controlled experiment on GitHub Copilot found that developers with access to Copilot completed the assigned programming task 55.8 percent faster than the control group in that study setup. That does not mean every team will see the same number in production, but it does support a practical point. Structured coding tasks and first draft work can often be accelerated with AI assistance.
The Opex win appears when this faster execution is combined with strong review and testing so the team reduces rework instead of pushing defects downstream.
This is also where it helps to connect AI usage to broader workflow changes, not isolated tool usage. If you already work with AI use cases in the software development lifecycle, this is the right frame.
Typical impact range in targeted rollouts: 10 to 15 percent Opex reduction, driven by lower effort on repetitive implementation work, faster onboarding support, and reduced developer load on low value coding tasks.
3) AI generated testing for QA and regression reduction
For many ISVs, this is the highest impact lever in the first year.
Teams often know what to test, but the effort required to create, maintain, and refresh tests keeps growing. AI can help generate unit tests, API tests, edge case scenarios, UI test scripts, and test data faster than manual authoring alone.
The important advantage is not just test generation. It is keeping test coverage aligned with change so regression effort does not grow unchecked.
This is where AI directly supports QA and release efficiency. If QA and regression are already your bottleneck, this is also the most natural point to connect readers to your Quality Assurance services.
Typical impact range in targeted rollouts: 12 to 18 percent Opex reduction when regression effort and manual QA are already major delivery bottlenecks.
Why these three can produce a real first year Opex reduction
When used together in the right sequence, these capabilities attack different parts of the same cost problem.
Code analysis reduces future rework.
AI assisted development reduces effort per change.
AI testing reduces regression load and defect leakage.
These ranges are not additive. The savings overlap. The 25 to 30 percent outcome comes from compounding improvements across rework reduction, QA efficiency, and lower maintenance drag, not by stacking percentages mechanically.
That is how teams can reach a credible 25 to 30 percent Opex reduction over time without a risky rewrite.
What this looks like in practice: real Opex reduction patterns
The exact numbers vary by codebase maturity, release process, and QA discipline. But the pattern is consistent when teams apply AI to regression, rework, and maintenance heavy workflows first.
Example pattern 1: SaaS case management product
A product team focused first on regression effort and escaped defects in high change modules. By prioritizing AI assisted test generation and earlier defect detection in review workflows, they reduced regression cycle time significantly, cut escaped defects, and moved from longer release cycles toward a tighter weekly release rhythm.
Strong - Representative outcomes from this kind of rollout:
up to 52 percent reduction in regression cycle time
up to 38 percent drop in escaped defects
release cycle compression, such as moving from multi week cadence toward weekly releases
Example pattern 2: FinTech ISV with heavy QA overhead
In QA heavy environments, the biggest win often comes from AI assisted test case generation and regression coverage expansion, not broad code generation. Teams reduce manual QA dependency, improve repeatability, and shorten validation effort for routine releases.
Strong - Representative outcomes from this kind of rollout:
AI generated tests replacing a large share of manual QA effort in targeted workflows
measurable drop in engineering overhead, often in the high teens to high twenties
faster onboarding because engineers can rely on AI support for code understanding and test scaffolding
Example pattern 3: Cloud logistics platform with legacy drag
For products with legacy module sprawl, AI driven code analysis and maintenance focused rollout can reduce refactoring effort and increase throughput by improving prioritization. Teams stop spreading effort across the whole codebase and start fixing the modules that generate the most cost.
Strong - Representative outcomes from this kind of rollout:
substantial reduction in legacy refactoring effort, including ~40 percent in targeted areas
improved developer throughput
faster reduction of recurring debt backlog when fixes are prioritized by cost impact rather than code age
The point is not to promise one exact number. The point is to show where the gains usually come from first: regression, rework, and maintenance friction.
Reduce Engineering Opex Without Disrupting Delivery
Identify where AI can reduce regression, maintenance, and validation effort before large transformation initiatives.
The rollout plan that works without disrupting delivery
Most teams do not fail because AI tools are weak. They fail because they introduce them in the wrong order.
If your goal is engineering Opex reduction, the question is not which AI feature looks impressive in a demo. The question is where recurring effort can be reduced fastest without increasing risk.
Step 1: Baseline the leaks before buying into velocity claims
Start with a simple baseline for the last one or two quarters.
Track:
regression cycle time
escaped defects (bug leakage) per release or per month
PR cycle time
maintenance share of sprint capacity
onboarding time to meaningful contribution
hotspot modules with high incidents or high change churn
Do not rely on story points alone. Opex savings often show up as reduced drag, fewer interruptions, and less rework.
If you cannot see where the money is leaking, you will automate the wrong work.
Step 2: Run code analysis on the most expensive modules first
Start where cost is already high.
Target modules with frequent bugs, repeat incidents, low coverage, slow reviews, and heavy dependence on senior engineers. AI analysis can surface duplication, fragile code paths, and missing tests in the areas where every avoided defect has high payoff.
The goal is a ranked backlog of high return fixes, not a broad debt cleanup program.
This is also where many teams create their first real Opex win because they stop treating legacy code as one giant problem and start prioritizing the parts of the system that generate the most maintenance cost.
Step 3: Reduce regression overhead before broad coding assistant rollout
A lot of teams start with coding assistants. In many cases, the faster Opex win is regression reduction.
Begin with your most important customer workflows and use AI to accelerate:
unit tests for changed code
API regression tests
edge case coverage
test data generation
refresh of outdated test scenarios
This reduces manual QA effort and improves release confidence. It also creates a cleaner path for future AI assisted development because your verification layer gets stronger first.
The economics behind this are straightforward. NIST’s report on software testing emphasizes that improved testing infrastructure can remove more bugs before release, detect bugs earlier in the development process, and locate the source of bugs faster, which reduces downstream correction cost and effort.
This is exactly why AI generated testing is not just a QA improvement story. It is an engineering Opex reduction story.
If QA and regression are already your bottleneck, this is the natural place to connect the reader to your Quality Assurance services.
Step 4: Standardize AI assisted development for approved use cases
Once regression drag starts improving, scale AI assisted development in a controlled way.
Do not treat AI as open ended for everything. Standardize a narrow set of high value use cases first:
scaffolding and boilerplate
wrappers and predictable transformations
test and mock generation
code explanation for onboarding
refactoring suggestions for low risk modules
documentation summaries and change notes
This protects review quality and makes adoption measurable. It also reduces tool confusion across teams.
This is where a broader AI in the software development lifecycle perspective helps because the value is not just coding speed. It is workflow coordination across build, test, review, and maintenance.
Step 5: Add AI assisted code review and maintenance support
At this stage, AI can be used to catch maintainability issues earlier, highlight missing edge case handling, and support issue triage and bug reproduction work.
This is where savings start to compound because fewer avoidable problems enter QA and production, and maintenance work becomes cheaper to process.
For ISVs with mature products, this often matters more than feature acceleration because maintenance effort is what keeps quietly consuming budget.
First 30 days and first quarter
First 30 days
baseline Opex leak points
select 2 to 3 high cost modules
run AI code analysis on those modules
pilot AI testing on one critical workflow
define approved AI development use cases
First quarter
expand AI testing across top regression paths
standardize AI assisted development for repeatable work
introduce AI assisted code review in PR flow
track changes in regression time, escaped defects, and PR cycle time
prioritize the next set of modules using actual cost data
How to measure results and avoid the traps
This is the section that separates a real engineering strategy from a tool rollout story.
A lot of teams feel faster after introducing AI. That is not enough. If the goal is reducing engineering Opex, the proof has to show up in operational metrics.
Measure outcomes, not activity
To prove Opex reduction, track the places where cost leaks:
Delivery and effort
PR cycle time
lead time for change
share of sprint capacity spent on maintenance and bug work
Quality and rework
escaped defects (bug leakage)
defect reopen rate
time to diagnose and fix production defects
rework after QA and review feedback
QA and regression
regression cycle time
release frequency
percentage of regression automated for top workflows
test maintenance effort
Maintenance drag
maintenance backlog growth rate
issue triage and reproduction effort
hotspot modules by incident count and change churn
If these numbers move together in the right direction, your Opex case becomes credible. If only coding output increases while QA and production support costs rise, your Opex did not improve.
Be honest about where AI can fail
AI productivity gains are not universal. A 2025 METR randomized controlled trial on experienced open source developers working in their own repositories found that AI tool use made participants slower in that specific setting. METR reported an average slowdown of about 19 percent.
This is not a reason to reject AI. It is a reason to implement it correctly.
The lesson is exactly what engineering leaders need to hear. AI reduces Opex when it is applied to the right work and governed with the right controls.
The guardrails that keep AI from increasing cost
Verification debt
Teams generate code faster than they can review and validate it. Output rises, but hidden defects rise too.
Fix: keep review standards high and require tests for AI assisted changes.
Test volume without test quality
AI generated tests can inflate coverage on paper while adding brittle, low value tests that slow CI and increase maintenance effort.
Fix: prioritize top workflows, review tests for signal, and track flaky test rate as a cost metric.
Tool sprawl
Different teams adopt different AI tools with no shared standards, creating inconsistent output and governance pain.
Fix: standardize approved use cases and align AI usage with existing SDLC and release controls.
Starting in the wrong place
If regression and QA are your biggest cost problem but you start with code generation demos, coding speed may improve while delivery still stays blocked.
Fix: start where recurring effort is highest: regression, defect prevention, and maintenance friction.
Why ISVs should start now
Delaying AI adoption does not keep engineering Opex flat. It usually increases the cost of the same work you are already doing.
As products grow, delaying practical AI rollout tends to increase:
maintenance backlog
time to market
cost of updates
developer attrition risk in teams carrying too much repetitive work
AI does not replace engineers. It removes the work engineers hate the most, especially repetitive implementation, avoidable rework, and slow manual validation loops.
That is why the strongest starting point is not a broad AI transformation program. It is a focused Opex reduction plan tied to delivery, QA, and maintenance metrics.
AI does not cut engineering Opex because it is fashionable. It cuts engineering Opex when it removes repetitive effort, shifts defect detection earlier, and reduces maintenance drag in the parts of the product that already cost you the most.
For most ISVs, the best starting points are AI driven code analysis, AI generated testing for regression heavy workflows, and AI assisted development for repeatable implementation work. Start there, measure operational impact, and the 25 to 30 percent result becomes something you can defend in a budget review.
If you want to move from discussion to a practical roadmap, explore our Software Maintenance Services as a starting point for an engineering Opex reduction assessment across dev, QA, and maintenance.
